原文翻译自Building an International Consortium for Tracking Coronavirus Health Status。 上图为新冠病毒普查组织官方网页。
作者:Eran Segal, Feng Zhang, Xihong Lin, Gary King, Ophir Shalem, Smadar Shilo, William E. Allen, Yonatan H. Grad, Casey S. Greene, Faisal Alquaddoomi, Simon Anders, Ran Balicer, Tal Bauman, Ximena Bonilla, Gisel Booman, Andrew T. Chan, Ori Cohen, Silvano Coletti, Natalie Davidson, Yuval Dor, David A. Drew, Olivier Elemento, Georgina Evans, Phil Ewels, Joshua Gale, Amir Gavrieli, Benjamin Geiger, Iman Hajirasouliha, Roman Jerala, Andre Kahles, Olli Kallioniemi, Ayya Keshet, Gregory Landua, Tomer Meir, Aline Muller, Long H. Nguyen, Matej Oresic, Svetlana Ovchinnikova, Hedi Peterson, Jay Rajagopal, Gunnar Rätsch, Hagai Rossman, Johan Rung, Andrea Sboner, Alexandros Sigaras, Tim Spector, Ron Steinherz, Irene Stevens, Jaak Vilo, Paul Wilmes, CCC (Coronavirus Census Collective)
翻译:Ging Lam
校对:鲁宇
译文最早分享于“Sociological理论大缸”公众号
从个人和全球层面来看,信息都是我们抗击流行病最得力的防护武器。对个人而言,信息可以帮助我们做决策,并为我们提供安全感。对全球共同体而言,信息可以为政策制定提供依据,并为COVID-19疾病的流行提供关键见解。然而,要充分发挥信息的力量,需要数据规模巨大并且可以被访问。为实现这一目标,我们正行动起来成立一个国际联盟——新冠病毒普查组织(Coronavirus Census Collective,简称CCC),该组织将形成一个枢纽机构,以整合多种数据源信息,使之可被用于理解、监控、预测和防治全球性流行疾病(图1)。这些数据源可能包括通过调查(包括移动应用程序)采集的自报(self-reported)健康状况、诊断实验室的检测结果以及其他静态和实时的地理空间数据。这项跟踪和共享信息的集体努力将在以下方面起到不可估量的作用:预测疾病爆发的热点地区、识别哪些因素控制了传播速度、为即时政策决定提供信息、评估卫生组织控制流行病的措施有效性,以及提供有关新冠病毒致病源的关键见解等。它还将有助于个人及时获悉当前瞬息万变的情况,并助力于减缓疾病蔓延的其他全球性努力。
在过去几周时间里,世界各地已采取若干积极举措,利用每日自报症状数据作为追踪疾病传播、预测疫情发生地点、指导人口措施(guide population measures)及帮助分配卫生保健资源。本文的目的正是倡议对这些努力行动进行规范,并发起一项协同工作(collaborative effort),在确保参与者隐私得到保护的同时,促进全球利益最大化。
新冠病毒在全球的迅速传播,导致世界卫生组织在2020年3月11日宣布其构成大流行。病例爆发的影响因素之一正是缺乏“谁被感染了”的信息,并很大程度上是由于没有足够多的人接受检测。在美国等许多国家,健康隐私法进一步加剧了这一问题。而在韩国和新加坡等检测更为积极和透明的国家,疾病的传播速度已大大减缓。虽然世界各地正竭尽全力大幅提高检测能力,但采用技术驱动方法(technology-driven approaches)收集自报信息可以满足当前迫切需求,并补充官方诊断结果。这类方法曾用于追踪其他疾病,特别是流感 。假以时日,受隐私保护的有关个人健康状况的信息被自愿收集,将使研究人员能够利用这些数据来预测、回应和了解新冠病毒的传播。鉴于该疾病和我们社会的全球一体本质(global nature),我们的目的是成立一个国际联盟(暂命名为新冠病毒普查组织)作为收集这类数据的枢纽机构,并搭建一个全球流行病学数据收集和分析的整合平台。
新冠病毒普查组织致力拯救人类生命,通过在保护隐私的前提下尽最大可能公开分享信息。这一基础机构可以立即在当前新冠病毒流行病中发挥作用,也可以用于应对未来可能出现或目前存在的其他疾病。尽管我们乐观地认为诊断检测能力将会迅速提高,但检测可能永远无法覆盖全球所有人口,因此迫切需要收集关于人口层级(population level)的自报症状和健康状况的额外数据。此外,我们计划整合不断增长的官方诊断检测数据和其他实时信息数据,以更好地评估确诊患者的症状特征,并改进我们的计算模型。从长远来看,对个人健康状况的广泛调查将成为了解疾病爆发的丰富信息来源,指导我们进行政策制定,并确保世界能够更好地应对未来的大流行病。大自然已向我们抛出一个前所未有、无国界的问题。现在正是我们拿出自己的全球解决方案做出回应的时候——那就是信息。无论是现在抑或将来,我们可以通过共同努力,果断地采取行动,最大化地增进全人类健康。
对信息的需求
早期对中国湖北新冠病毒疫情的流行病学研究表明,减缓该病毒的传播速度对于减少其扩散具有压倒性的价值。而要减缓病毒的传播速度,需要信息来说明谁被感染了,以及这些感染者在哪里。中国正是通过对大量疑似感染者进行检测,以及对检测呈阳性的个人进行隔离,实现了这一目标。韩国是新冠病毒第二轮爆发地,韩国政府官员采取的办法是,结合大规模检测和公开透明数据,共享确诊患者的位置状况。虽然这种办法的成功之处显而易见,但其并没有被广泛执行。例如,意大利就没有采用这种办法,他们的感染率在近期急剧上升,缺乏普遍检测可能是其中的原因。虽然中国和韩国的办法取得了成功,但它面临两个主要限制,阻碍其在绝大多数其他国家的应用:其一是其他国家的诊断检测能力有限,其二是其他国家的个人和健康隐私法更加严格。例如,在新一轮疫情爆发中心的美国,绝大多数州仍未进行大规模检测。在美国多个州所记录到社区疫情的几周时间里,检测对象仍仅限于有严重症状和曾到过早期疾病传播的地区的人(如中国、韩国、日本和伊朗等)。由于检测能力有限,美国社会被报告为“确诊病例”的数字并不能反映真实的确诊数字或病毒的实际传播速度 。事实上,许多病毒携带者只表现出轻微的症状而不去检测,这也是我们对疾病的冲击缺乏了解的原因。
采用技术驱动的方法(technology-driven approaches)自愿采集关于健康状况的自报数据可以克服以上限制。这些数据可以与其他相关的实时数据资源进一步整合,例如气象数据、某一时间和地点的人口密度,以及其他动态数据源。这些数据结合在一起可以提供关键信息,立即用于对疾病人群的早期识别,达到减缓疾病传播的目的。
我们在美国和以色列开展了几项类似的工作。在美国,我们开发了一个名为HowWeFeel的应用程序 ,这个程序可以对患者的健康状况进行30秒的调查,以收集流行病学数据(图2)。CovidNearYou 和covid19-EIPM 则是网站应用,两者均使用了开放存储的可视化工具,以完全匿名的方式收集相同的信息(图3和图4)。在以色列,我们开发了Predict-Corona ,一个每天只需1分钟的线上调查,要求受访者测量体温,并报告他们是否表现出任何与确证患者相同的症状。在这一调查发布后的大约10天时间里,已经获得超过30万个回复。我们已然看到这一方法在探测未来疫情爆发区域的潜力(图5)。
图2 HowWeFeel的应用程序
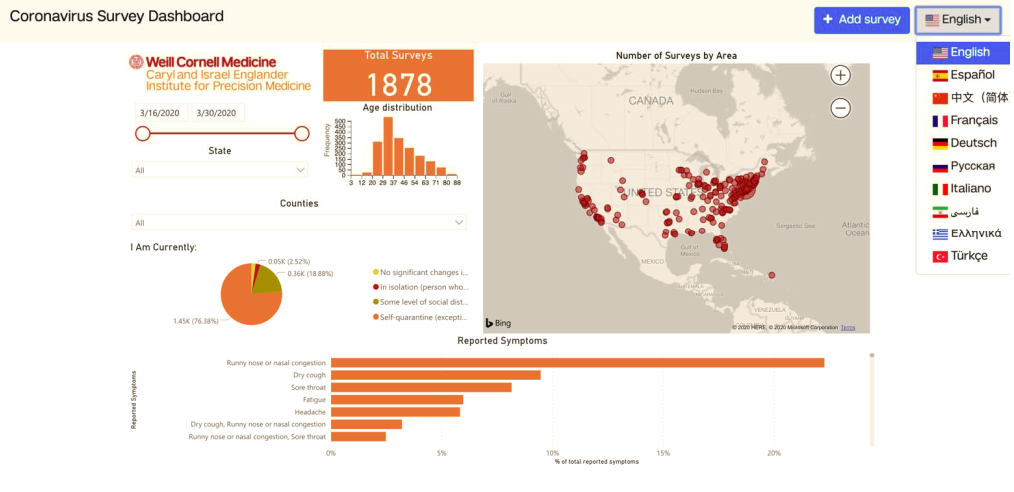
图3 covid19-EIPM网站应用

图4 covid19-EIPM调查问卷
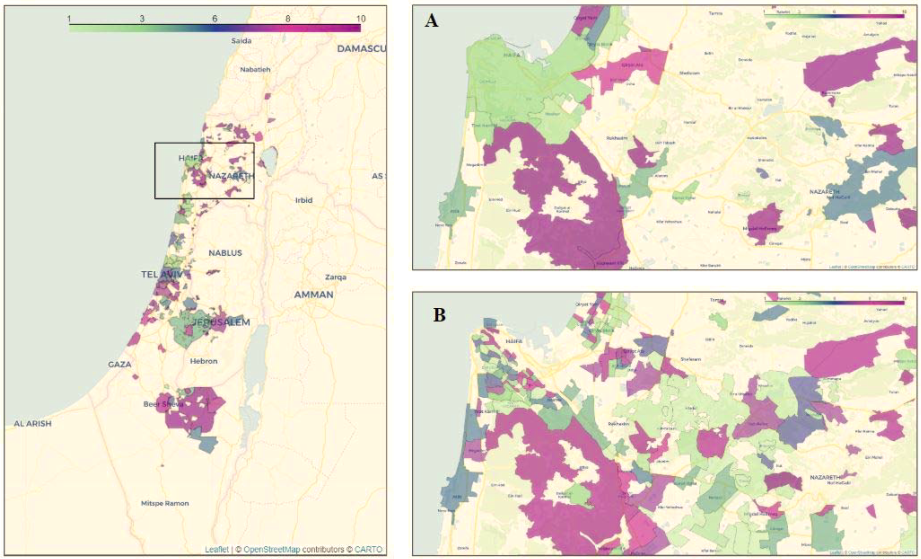
图5 基于Predict-Corona数据的症状分布图
这项工作与其他国家进行的类似调查举措并驾齐驱,如英国的新冠病毒症状追踪系统(Covid Symptom Tracker) 、瑞士的新冠病毒调查项目(the COVID-19: CH Survey Project) 以及斯洛文尼亚的新冠病毒肺炎的自报系统(Covid-19 self-reporting) 。在美国和英国,我们已建成新冠病毒流行病联合组织(Coronavirus Pandemic Consortium) ,使用病毒症状跟踪系统,把国际前瞻性研究、观察队列研究(如基于人口、临床等)和临床试验/研究整合到一起。
为了提高这些数据的统计效力,我们呼吁成立一个国际联盟即新冠病毒普查组织,来整合这些数据流,并提供一个统一的中央数据库,供世界各地的研究人员可靠地访问。除了确保数据的可比性之外,新冠病毒普查组织还将作为其他国家机构的一种资源,这些机构正在开展相似调查,目的是促进其在世界各地的快速部署。由于许多国家正在努力寻找应对这一流行病的最佳策略,我们认为,我们迫切需要全球协作努力,以获得可用于预测新冠病毒感染爆发的数据。
在开展这项全球工作的过程中,我们充分认识到既要照顾欠发达国家,也要照顾到代表性不足或社会经济地位较低的人口。例如在以色列,我们使用多种语言分发了我们的调查,邀请当地宗教社区的领袖参与其中,并通过希伯来语和阿拉伯语媒体对调查进行宣传,提高以色列各阶层的人参与本调查的程度。同样,HowWeFeel已经被翻译成20种语言,Covid19-EIPM目前支持10种不同语种。
一个收集和共享数据的框架
我们将收集各类调查回复,囊括新冠病毒相关的症状信、地理空间位置、发病时间等信息,以及年龄、既往病和合并症等人口学信息。这些数据将被收集起来,然后去除标识,并在分析之前进一步匿名化,以使研究人员在个人隐私得到保护的前提下共享和分析数据。因为参与者的隐私对我们的使命至关重要,我们将坚守在隐私保护技术的前沿,在必要之时开发新的方法,并尽可能地不断对其进行改进。我们的技术和APP应用程序的代码将是开源的,所以其他人可以根据自己的特殊情况进行调整,发现错误,或者帮助我们改进。我们的设想是,所有成员都在调查中使用一套共同的“核心”题目,但也可以根据当地的法规、研究人员个人兴趣和社区的需要,增加一些针对特定地区的题目。随着我们对新冠病毒的了解越来越多,这套核心题目可能会逐渐增加。
我们将建立一个联合通用数据模型(federated common data model),在确保不同国家的数据安全和隐私的同时,促进数据共享。为实现这一目标,我们将制定指导方针,确保从所有数据贡献者那里收集的基础数据模型能够很容易地合并和统一,并搭建起联合数据共享政策(consortium data sharing policy)。我们也将应用不同的方法,如差异化隐私功能,使研究人员能够在保证参与者隐私的同时,也能共享和分析数据。鉴于各地区的隐私保护条例各不相同,一些国家调查中的个体层面数据可能无法开放获取,但所有研究人员都可以获取差异隐私统计分析(differentially private statistical analyses)的结果。
这些数据将允许研究人员开展一些即时有用的分析。例如可以计算出在特定地理区域内有多少人出现病症或自报的官方检测结果。统计数据可以综合计算,也可以根据合并症及诸如年龄的人口学信息来进行计算。无论是总体上还是按地区或人口特征分层上,这都将有助于实时监测受访人群的健康状况。我们可以采用回归分析来探索与病症及检测结果相关的流行病学因素,可以采用空间分析来绘制病症发生率和阳性检验概率的地理统计图。另外,我们还可以采用聚类模型,基于多人同时报告相似症状的模式,识别可能已经爆发疫情的地区。这将为我们在病毒检测不充分的情况下,估计出表现病症个体的人口规模。对于那些检测阳性的参与者和检测阴性的参与者,我们能使用“量化”(有别于“分类”)的方法来精确估计新冠病毒的人口流行率,即便我们无法仅从症状上对个体进行可靠的分类。另一个潜在应用是评估各种社会疏离措施(social distancing measures)的有效性及其对减少病症人数的贡献。最后,我们可以采用滞后预测模型(lagged prediction models)来识别特定地理区域内报告的新冠病毒相关症状发生率的增长趋势。这些预测结果将可能有助于确定需要分配额外检测或医疗资源的范围。为最大限度提高数据收集效果,我们将提供一个应用程序编程接口(API),允许授权研究人员访问数据并进行额外的统计分析。
新冠病毒普查组织旨在进一步发挥自愿性自报健康信息的影响,并积极寻求世界各地研究人员的合作,在致力于保护个人隐私的同时尽量扩大这种做法的潜在收益。我们设想,新冠病毒普查组织将由一个理事会来协调工作。理事会将审查新成员资格,维护一个安全的中央数据储存库或联合多站点数据储存库,并开发出能使世界各地研究人员查询数据的机制。个人成员自己则应确保遵守当地的法律法规。